DuckDB
In this post, I want to explore the features and capabilities of DuckDB, an open-source, in-process SQL OLAP database management system written in C++11 that has been gaining popularity recently. According to what people have said, DuckDB is designed to be easy to use and flexible, allowing you to run complex queries on relational datasets using either local, file-based DuckDB instances or the cloud service MotherDuck.

One of the key goals of DuckDB is to make accessing data in common formats easy. It supports running queries directly on CSV, JSON, Parquet, and other file formats. DuckDB can also write query results directly to any of these formats.
I will cover some basic features of DuckDB and explore some ideas for how it can be applied to your Data Engineering or Data Analytics tasks.
- 1. Installation single binary
- 2. Reading/Writing CSV Files
- 3. Reading/Writing Parquet Files
- 4. Partitioned Writes
- 5. Using DuckDB in Rust
- 6. Using DuckDB in Python
- 7. Online DuckDB Shell
- 8. Serverless DuckDB over S3
- 9. DuckDB with dbt
- 10. DuckDB with Apache Airflow
- 11. Modern Data Stack in a Box with DuckDB
- 13. Conclusion
- 14. References
1. Installation single binary
Installing DuckDB is easy. You can grab the binary directly from the DuckDB website (https://duckdb.org/docs/archive/0.8.1/installation) or use a package manager such as Homebrew on MacOS.
brew install duckdb
Download the binary
wget https://github.com/duckdb/duckdb/releases/download/v0.8.1/duckdb_cli-osx-universal.zip
unzip duckdb_cli-osx-universal.zip && rm duckdb_cli-osx-universal.zip
./duckdb
2. Reading/Writing CSV Files
Reading a CSV file from disk is straightforward with DuckDB. You can either read the file directly using a SELECT statement or create a table and read the file into it using the COPY command.
-- read a CSV file from disk, auto-infer options
SELECT * FROM 'flights.csv';
SELECT * FROM read_csv('flights.csv');
SELECT * FROM read_csv('flights.csv', AUTO_DETECT=TRUE);
-- read_csv with custom options
SELECT * FROM read_csv('flights.csv', delim='|', header=True, columns={'FlightDate': 'DATE', 'UniqueCarrier': 'VARCHAR', 'OriginCityName': 'VARCHAR', 'DestCityName': 'VARCHAR'});
-- read a CSV file into a table
CREATE TABLE ontime(FlightDate DATE, UniqueCarrier VARCHAR, OriginCityName VARCHAR, DestCityName VARCHAR);
COPY ontime FROM 'flights.csv' (AUTO_DETECT TRUE);
Reading from multiple files
SELECT * FROM read_csv('flights/*.csv');
SELECT * FROM read_csv(['flights_001.csv', 'flights_002.csv']);
The read_csv_auto is the simplest method of loading CSV files: it automatically attempts to figure out the correct configuration of the CSV reader
SELECT * FROM read_csv_auto('flights.csv');
In the shell, you can also pipe the data from stdin directly to ./duckdb
# read a CSV from stdin, auto-infer options
cat data/csv/issue2471.csv | duckdb -c "select * from read_csv_auto('/dev/stdin')"
Reference to CSV Loading document to see more explain and example.
Writing CSV Files
COPY moves data between DuckDB and external files. COPY ... FROM imports data into DuckDB from an external file. COPY ... TO writes data from DuckDB to an external file. The COPY command can be used for CSV, PARQUET and JSON files.
-- write the result of a query to a CSV file
COPY (SELECT * FROM ontime) TO 'flights.csv' WITH (HEADER 1, DELIMITER '|');
More on the copy statement can be found here.
3. Reading/Writing Parquet Files
DuckDB can also read Parquet files using the read_parquet function. This function takes a filename and returns a relation containing the data from the Parquet file.
SELECT * FROM 'example.parquet';
SELECT * FROM read_parquet('example.parquet');
CREATE TABLE example AS SELECT * FROM 'example.parquet';
-- read all files that match the glob pattern
SELECT * FROM 'test/*.parquet';
The same as CSV, we can also write to Parquet file using COPY
4. Partitioned Writes
When the partition_by clause is specified for the COPY statement, the files are written in a hive partitioned folder hierarchy.
-- write a table to a hive partitioned data set of parquet files
COPY orders TO 'orders' (FORMAT PARQUET, PARTITION_BY (year, month));
-- write a table to a hive partitioned data set of CSV files, allowing overwrites
COPY orders TO 'orders' (FORMAT CSV, PARTITION_BY (year, month), OVERWRITE_OR_IGNORE 1);
orders
├── year=2022
│ ├── month=1
│ │ ├── data_1.parquet
│ │ └── data_2.parquet
│ └── month=2
│ └── data_1.parquet
└── year=2023
├── month=11
│ ├── data_1.parquet
│ └── data_2.parquet
└── month=12
└── data_1.parquet
References
5. Using DuckDB in Rust
The DuckDB Rust API can be installed from crates.io and see the docs.rs for details.
cargo add duckdb
Here is the example from their README.md. It attempts to expose an interface similar to rusqlite
use duckdb::{params, Connection, Result};
fn main() -> Result<()> {
let conn = Connection::open_in_memory()?;
// Querying
conn.execute(
"INSERT INTO person (name, data) VALUES (?, ?)",
params!["duyet", "{}"],
)?;
let mut stmt = conn.prepare("SELECT id, name, data FROM person")?;
let person_iter = stmt.query_map([], |row| {
Ok(Person {
id: row.get(0)?,
name: row.get(1)?,
data: row.get(2)?,
})
})?;
for person in person_iter {
println!("Found person {:?}", person.unwrap());
}
Ok(())
}
6. Using DuckDB in Python
DuckDB can be used from Python using the DuckDB Python API. The API can be installed using pip: pip install duckdb.
import duckdb
duckdb.sql('SELECT 42').show()
DuckDB can ingest data from a wide variety of formats - both on-disk and in-memory.
import duckdb
duckdb.read_csv('example.csv') # read a CSV file into a Relation
duckdb.read_parquet('example.parquet') # read a Parquet file into a Relation
duckdb.read_json('example.json') # read a JSON file into a Relation
DuckDB can also directly query Pandas DataFrames, Polars DataFrames, and Arrow tables.
import duckdb
# directly query a Pandas DataFrame
import pandas as pd
pandas_df = pd.DataFrame({'a': [42]})
duckdb.sql('SELECT * FROM pandas_df')
# directly query a Polars DataFrame
import polars as pl
polars_df = pl.DataFrame({'a': [42]})
duckdb.sql('SELECT * FROM polars_df')
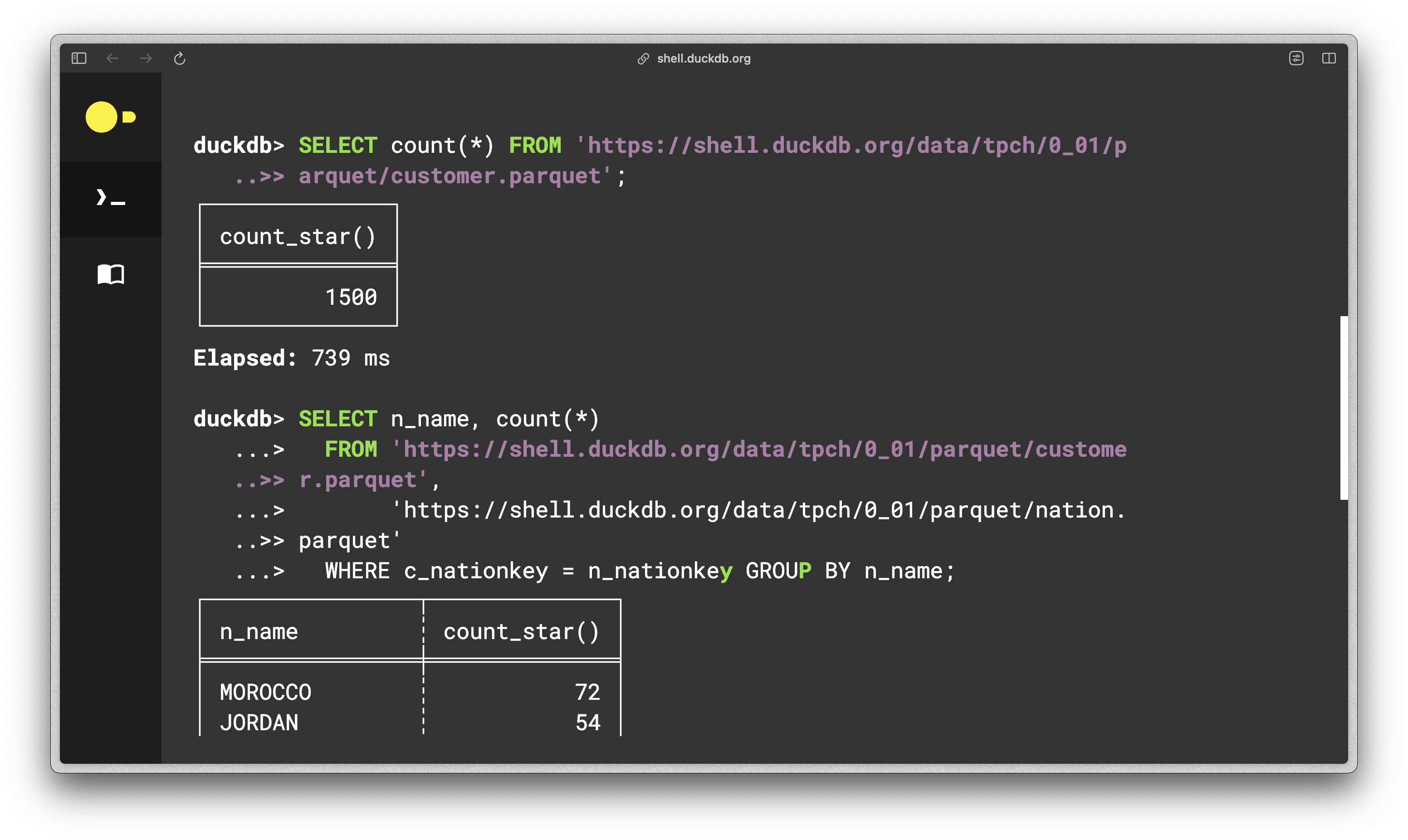
7. Online DuckDB Shell
DuckDB has been compiled to WebAssembly, so it can run inside any browser on any device. A great starting point is to read the DuckDB-Wasm launch blog post to integrate DuckDB-Wasm to your web application.
8. Serverless DuckDB over S3
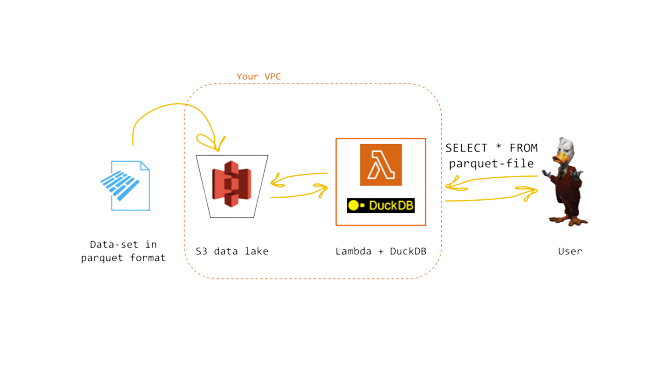
This cool project helping you running DuckDB serverless over a data lake on S3 using AWS Lambda. Seeing the blog post for more detail.
9. DuckDB with dbt
dbt is the best way to manage a collection of data transformations written in SQL or Python for analytics and data science. Yes we can use it together via this adapter dbt-duckdb. Seeing the document for more detail.

10. DuckDB with Apache Airflow
DuckDB appears to be a suitable option for basic data processing of small datasets within Airflow. You can use the duckdb Python package directly in your @task decorated tasks.
from airflow.decorators import dag, task
from pendulum import datetime, yesterday
import duckdb
import pandas as pd
@dag(start_date=yesterday(), schedule=None, catchup=False)
def duckdb_dag():
@task
def create_pandas_df():
"Create a pandas DataFrame with toy data and return it."
return pd.DataFrame({"colors": ["blue", "red", "yellow"], "numbers": [2, 3, 4]})
@task
def create_duckdb_table_from_pandas_df(df):
"Create a table in DuckDB based on a pandas DataFrame and query it"
# change the path to connect to a different database
conn = duckdb.connect("my_garden_ducks.db")
conn.sql("""
CREATE TABLE IF NOT EXISTS ducks_garden AS
SELECT * FROM ducks_in_my_garden_df;
""")
sets_of_ducks = conn.sql("SELECT numbers FROM ducks_garden;").fetchall()
for ducks in sets_of_ducks:
print("quack " * ducks[0])
create_duckdb_table_from_pandas_df(df=create_pandas_df())
duckdb_dag()
For additional tutorials, please refer to this document.
11. Modern Data Stack in a Box with DuckDB

If is a data engineer, you should check out this post.
There is a large volume of literature (1, 2, 3) about scaling data pipelines. “Use Kafka! Build a lake house! Don’t build a lake house, use Snowflake! Don’t use Snowflake, use XYZ!” However, with advances in hardware and the rapid maturation of data software, there is a simpler approach. This article will light up the path to highly performant single node analytics with an MDS-in-a-box open source stack: Meltano, DuckDB, dbt, & Apache Superset on Windows using Windows Subsystem for Linux (WSL). There are many options within the MDS, so if you are using another stack to build an MDS-in-a-box, please share it with the community on the DuckDB Twitter, GitHub, or Discord, or the dbt slack! Or just stop by for a friendly debate about our choice of tools!
12. DuckDB instead of Spark
Spark is a powerful tool for big data processing, but it can be too much for medium-sized datasets, resulting in significant overhead. If you're working with smaller datasets ranging from tenths to hundredths of gigabytes, you can use dbt and Duckdb as an alternative processing engine. This option may be suitable for your needs if your transformations are relatively straightforward, such as renaming columns or cleansing input data.
When it comes to performing data transformations on medium-sized datasets, using DBT with Duckdb can be more cost-effective than using Spark. Moreover, DuckDB may even be faster for such datasets.
Many of you might soon think about use dbt and Duckdb instead of Spark in data pipelines like this guy.

Image: dataminded
13. Conclusion
One of the things I like about DuckDB is its simplicity and portability. Similar to SQLite, I can install and use it with a single binary or easily embed it into my application.
For those who work with relational datasets, DuckDB is an excellent tool to consider. Its flexibility and user-friendly nature make it a great choice for both data analysts and engineers. Whether you need to import data from CSV or Parquet files or query Pandas or Polars DataFrames, DuckDB has got you covered. Give it a try today and see how it can aid you in your next project.
14. References
- Official Documentation - Official DuckDB documentation.
- Official Blog - Official DuckDB blog.
- davidgasquez/awesome-duckdb - Github
- DuckDB setup - GitHub Action to install DuckDB in CI.
- Online DuckDB Shell - Online DuckDB shell powered by WebAssembly.
- The Case for In-Process Analytics (Slides)