Tại sao nên triển khai Apache Spark trên Kubernetes
Note: This post is over 5 years old. The information may be outdated.
Apache Spark đã quá nổi tiếng trong thế giới Data Engineering và Big Data. Kubernetes cũng ngày càng phổ biến tương tự, là một hệ thống quản lý deployment và scaling application. Bài viết này đề cập đến một số lợi ích khi triển khai Apache Spark trên hệ thống Kubernetes.
Có một số lý do bạn bạn nên triển khai Apache Spark trên Kubernetes.
- Native option
- Tận dụng sức mạnh của công nghệ Container
- Monitoring và Logging
- Namespace / Resource quotas
- Node selectors, Service Account
Native option
Kubernetes đã trở thành native option cho Spark resource manager kể từ version 2.3 (thay vì Hadoop Yarn, Apache Mesos như trước). Trang tài liệu của Apache Spark có hướng dẫn rất đầy đủ các cài đặt để chạy Spark trên Kubernetes: https://spark.apache.org/docs/latest/running-on-kubernetes.html
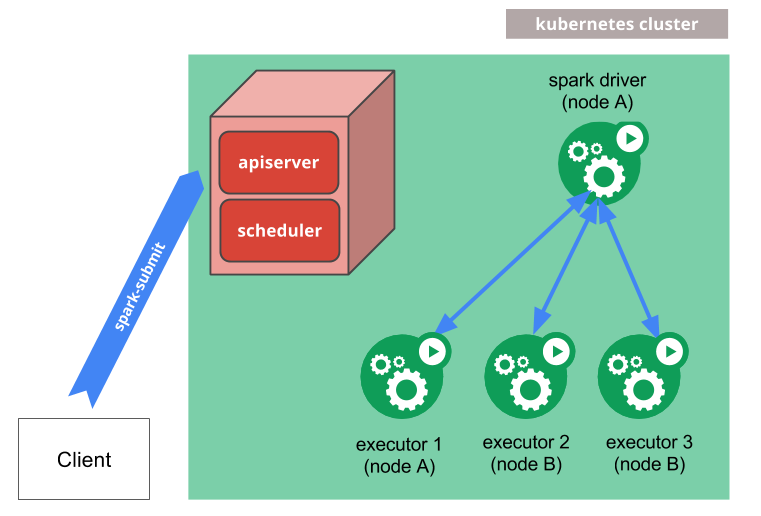
Spark sẽ tạo một Spark driver bằng một Kubernetes pod.
- Driver này sẽ tạo các Executors, mỗi executor cũng là một Kubernetes pods và kết nối các Pod này lại với nhau, sau đó thực thi application code.
- Sau khi ứng dụng complete, các Executor pods sẽ bị terminate. Nhưng driver pod sẽ chuyển sang trạng thái
completedđể giữ logs cho đến khi nó bị xóa bởi garbage collected hoặc manually cleaned up.
Tận dụng sức mạnh của công nghệ Container
Chạy Spark trên Kubernetes dưới dạng các pod container, ta tận dụng được nhiều ưu điểm của công nghệ container:
- Đóng gói Spark application, package và dependencies vào cùng một container duy nhất, tránh xung đột phiên bản thư viện với Hadoop hay ứng dụng khác
- Version control bằng cách sử dụng image tags.
- Với cách này, bạn thậm chí còn có thể sử dụng nhiều phiên bản Spark trên cùng một cluster một cách dễ dàng. Ví dụ bạn có thể chạy Spark 2.3 và Spark 3.0 mà không hề có sự xung đột nào.
Monitoring và Logging
Tận dụng monitoring và logging của Kubernetes: Kubernetes rất mạnh trong việc monitoring các pod, service, node. Bạn có thể dễ dàng xuất log hoặc metrics ra một hệ thống khác như Graylog, Elasticsearch, Stackdriver, Prometheus, Statd ... bằng cách cài thêm 1 pod logging agent hoặc thêm 1 sidecar container để export.
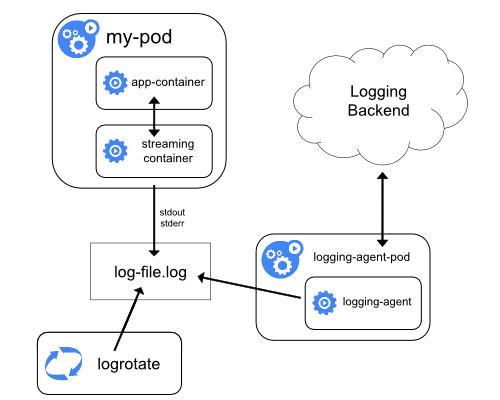
Tham khảo thêm:
- Logging Using Elasticsearch and Kibana
- Logging Using Stackdriver
- Monitor Node Health
- Tools for Monitoring Resources
- Setting up, Managing & Monitoring Spark on Kubernetes
Namespace / Resource quotas
Dễ dàng quản lý resources, phân chia giới hạn tài nguyên cho nhiều team bằng cách sử dụng Kubernetes namespace và resource quotas.
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu
namespace: cluster-spark-staging
spec:
hard:
requests.cpu: 500
limits.cpu: 800
requests.memory: "100Gi"
limits.memory: "300Gi"
pods: 500000
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu
namespace: cluster-spark-production
spec:
hard:
requests.cpu: 2000
limits.cpu: 3000
requests.memory: "800Gi"
limits.memory: "1500Gi"
pods: 500000
---
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-log-processing
namespace: cluster-spark-production # <-----
spec:
type: Scala
mode: cluster
...
Node selectors, Service Account
Sử dụng Kubernetes node selectors để kiểm soát việc chạy Spark trên các loại máy khác nhau tùy theo mục đích của Spark app.
Ngoài ra Kubernetes service account dùng để quản lý permission sử dụng Role và ClusterRole, cho phép team nào có thể sử dụng cluster nào.
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-log-processing
namespace: data-production
spec:
type: Scala
mode: cluster
image: gcr.io/spark/spark:v3.0.0
mainClass: org.duyet.spark.transformation.LogProcessing
mainApplicationFile: s3://duyet/spark/etl/jars/spark-log-processing_2.12-3.0.0.jar
nodeSelector:
disktype: ssd
clusterTeam: team-duyet
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: cluster-label
operator: In
values:
- cluster-realtime
- cluster-production
Kết luận
Mặc dù có nhiều điểm mạnh, Kubernetes scheduler support for Spark vẫn cần nhiều cải thiện do vẫn còn rất mới mẻ, so với thời gian phát triển nhiều năm của YARN hay Mesos.
Bạn có thể tham khảo các cách để chạy ứng dụng Spark trên Kubernetes như spark-submit hay Spark Operator ở bài viết này và tối ưu hóa Spark trên Kubernetes của AWS tại đây.