Information Retrieval - Vector Space Model
Note: This post is over 6 years old. The information may be outdated.
Một hệ thống tìm kiếm thông tin (Information Retrieval - IR) là một hệ thống tra cứu (thường là các tài liệu văn bản) từ một nguồn không có cấu trúc tự nhiên (thường là văn bản), chứa đựng một số thông tin nào đó từ một tập hợp lớn.
Information Retrieval
- Phần 1: Vector Space Model
- Phần 2: Đánh giá hệ thống Information Retrieval
Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
Khi nói đến IR là nói đến cách tổ chức trình bày, lưu trữ và tìm kiếm. Tùy kiểu dữ liệu khác nhau mà có các cách thức khác nhau. Một số ví dụ dễ thấy của IR như các cỗ máy tìm kiếm (Search Engine).
Trong các bài biết về IR mình chủ yếu sẽ nói về cách tổ chức và kỹ thuật xếp hạng tài liệu khi ta tra cứu bằng các truy vấn. Một trong những kỹ thuật phổ biến trong Information Retrieval đó là Vector Space Model (dịch ra là mô hình không gian vector).
Kiến trúc của một hệ thống IR
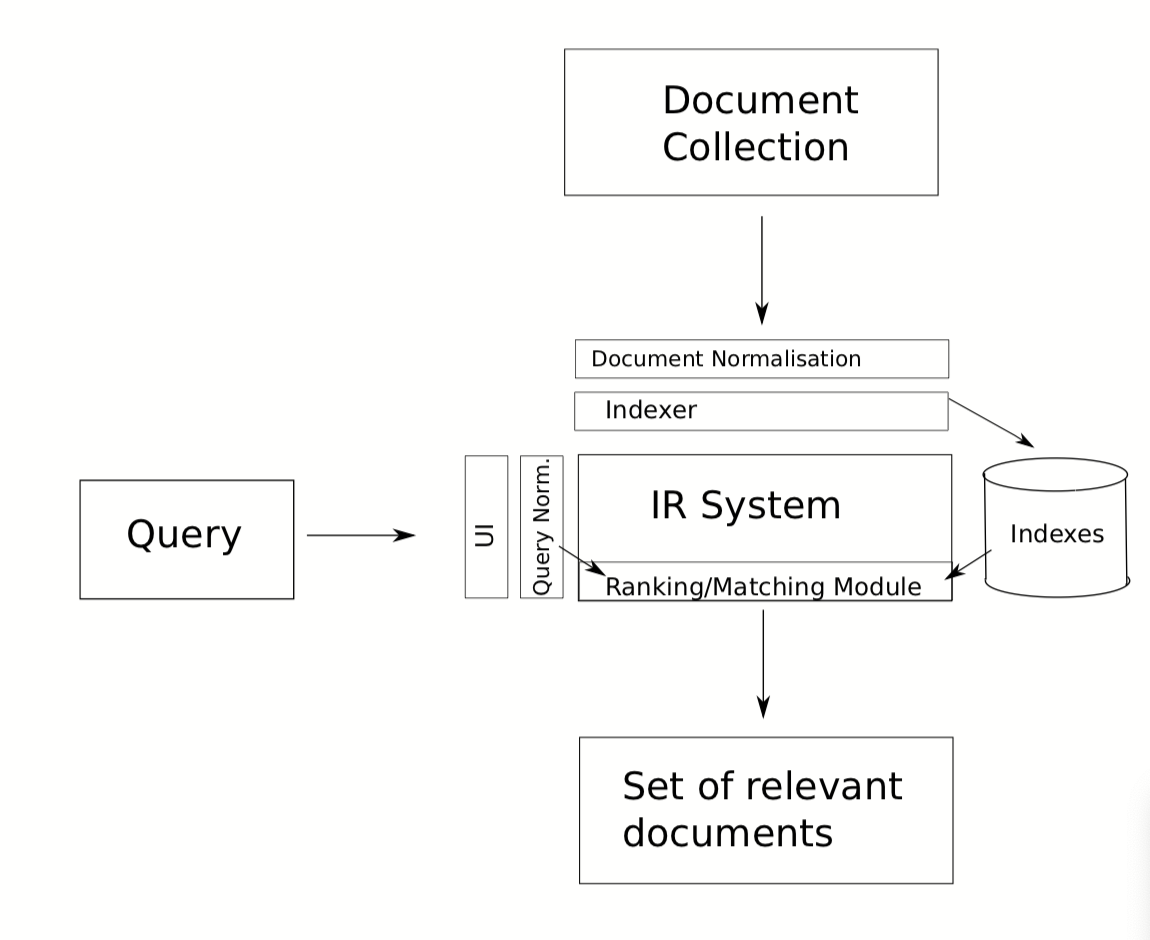
Ký hiệu
Ta có một số ký hiệu sau:
- Query (Câu truy vấn)
- Tài liệu (Documents)
- Collection
- : relevance giữa và
- : hàm biểu diễn tài liệu
- : hàm biểu diễn truy vấn
1. Ý tưởng của Vector Space Model
Với mỗi truy vấn, hệ thống tìm kiếm sẽ sử dụng một độ đo để tính độ tương đồng giữa truy vấn (query) đó với các tài liệu (docs), từ đó xếp dạng được kết quả trả về.
Ý tưởng của Vector Space Model là biểu diễn văn bản và các câu truy vấn dưới dạng Vector, của docs và của query sẽ cho kết quả là các vector. Sau đó tính độ tương đồng của query với từng documents theo công thức để tìm ra docs vào phù hợp nhất với query.
-
Biến đổi các queries và docs thành dạng vector như sau:
-
Từ đó sử dụng một độ đo khoảng cách trên vector và để xếp hạng các docs.

Relevant = Similarity
Các giả định:
-
Các query và documents được biểu diễn cùng một định dạng với nhau (cùng kích thước, cách biểu diễn trọng số).
-
-
có thể được tính bằng bất cứ độ đo trên vector nào (e.g. Euclidean, Consine Similarity, ... )
Các vấn đề đặt ra
Các vấn đề cần đặt ra là:
- Làm thế nào để biểu diễn và , công thức tính , .
- Làm thể nào để định nghĩa công thức tính độ tương đồng
2. Concept vectors
Biểu diễn documents và query bởi các concept vectors
- Mỗi concept biểu diễn một chiều
- K concepts biểu diễn một không gian nhiều chiều.
- Ta cần định nghĩa trọng số (weight) cho từng chiều của vector.

3. Tìm trọng số (weights) cho vector
Cách xác định và tính weights cho vector là hết sức quan trọng, ảnh hưởng đến độ chính xác của các thuật toán xếp hạng. Việc các từ có trọng số khác nhau là do không phải các từ đều có sự quan trọng giống nhau, sử dụng số lần xuất hiện của các từ làm vector không phải là một cách tối ưu. Ở phương diện các documents, một vài từ có thể mang nhiều thông tin hơn các từ còn lại.
Có nhiều kỹ thuật tính trọng số: TF, IDF, TF-IDF, ...
a. TF: Term frequency
Từ nào xuất hiện nhiều trong câu thì quan trọng, công thức này sẽ đếm tuần suất xuất hiện các từ trong câu.
TF normalization: Do tùy độ dài ngắn khác nhau của từng câu, mà việc đếm tần suất các từ có thể không công bằng, một số kỹ thuật chuẩn hóa sau có thể giảm tránh được điều này,
- Chia cho độ dài câu.
b. IDF: Inverse document frequency
Từ nào xuất hiện nhiều trong mọi câu thì không mang nhiều ý nghĩa (ví dụ như a, the, are, thì, là, ...). Vì vậy trọng số IDF là nghịch đảo của tuần suất xuất hiện của các từ trong các documents.
Với:
- : số cài liệu trong tập corpus
- : số docs mà từ xuất hiện. Cộng 1 cho mẫu số để tránh trường hợp chia cho 0 nếu từ đó không xuất hiện trong copus .
c. TF-IDF: Term frequency - Inverse document frequency
Phép nhân giữa TD và IDF cho phép ta kết hợp cả 2 độ đo trên, từ vừa xuất hiện nhiều lần trong câu, vừa không phải là từ phổ biến xuất hiện trong mọi câu.
4. Các độ đo similarity
Sau khi có được các vector cho query và docs, ta tính được similarity bằng cách tính khoảng cách giữa các vector.
a. Euclidean distance
Công thức tính theo WiKi:
Nhược điểm:
- Docs dài hơn sẽ bị giảm hạn do chứa nhiều từ khác gây nhiễu, khiến khoảng cách xa hơn.
b. Manhattan
Manhattan distance hay còn gọi là L1 distance, tính khoảng cách 2 vector theo công thức
c. Độ đo góc
Việc tính xem các vector overlapped với nhau như thế nào cũng là một phép so sánh hay sử dụng, độ đo góc phổ biến là Cosine Similarity.
Sau khi biểu diễn dưới dạng vector và tính khoảng cách, ta xếp hạng được các tài liệu tìm kiếm với từng query vector.

5. Ưu và nhược điểm của Vector Space Model
a. Ưu điểm
- Dễ hiểu và dễ cài đặt
- Đã được nghiên cứu từ lâu và thực nghiệm cho kết quả tốt và khả thi
- Hiện tại là phương pháp được sử dụng rộng rãi
- Có nhiều công thức tính TF.IDF khác nhau.
b. Nhược điểm
- Để cho kết quả đúng đắn, ta giả định:
- Các câu là độc lập với nhau
- Các query và documents cùng loại với nhau
- Có nhiều tham số để hiệu chỉnh
- Bộ từ điển
- Tham số trong các hàm Normalize
- Threshold để chọn ra top kết quả
Series: Information Retrieval
Hệ thống tra cứu thông tin - Information Retrieval. Một hệ thống tìm kiếm thông tin (Information Retrieval - IR) là một hệ thống tra cứu (thường là các tài liệu văn bản) từ một nguồn không có cấu trúc tự nhiên (thường là văn bản), chứa đựng một số thông tin nào đó từ một tập hợp lớn. Một trong những kỹ thuật phổ biến trong Information Retrieval đó là Vector Space Model.
Trong bài này chúng ta sẽ tìm hiểu về cách đánh giá các hệ thống Information Retrieval, thách thức của việc đánh giá và các độ đo phổ biến như Precision/Accuracy, Recall, R-precision, F-measure, MAP, ...