NLP - Truyện Kiều Word2vec
Note: This post is over 8 years old. The information may be outdated.
Trong các dự án gần đây mình làm nhiều về Word2vec, khá có vẻ là useful trong việc biểu diễn word lên không gian vector (word embedding). Nói thêm về Word2vec, trong các dự án nghiên cứu W2V của Google còn khám phá được ra tính ngữ nghĩa, cú pháp của các từ ở một số mức độ nào đó. Ví dụ như bài toán King + Man - Woman = ? kinh điển dưới đây:
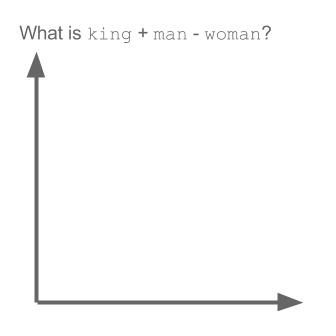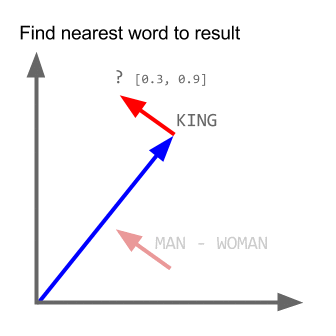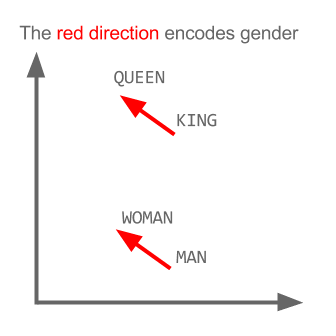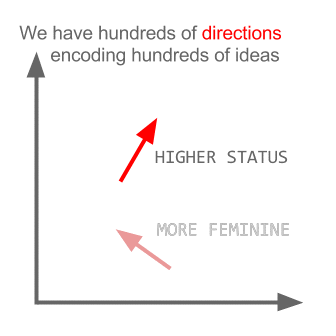
Sử dụng word2vec cho Truyện Kiều (Nguyễn Du), tuy không phải là một dataset lớn, nhưng biết đâu sẽ tìm ra mối liên hệ "bí ẩn" nào đó giữa Kiều và Mã Giám Sinh. Hay thật sự có phải chữ "Tài" đi với chữ "Tai" như Nguyễn Du đã viết?
Word vector là gì?
Trước tiên giới thiệu 1 chút về Word vector. Về cơ bản, đây chỉ là một vector trọng số, biểu diễn cho 1 từ, với số chiều cụ thể.
Ví dụ, 1-of-N (one-hot vector) sẽ mã hoá (encoding) các từ trong từ điển thành một vector có chiều dài N (tổng số lượng các từ trong từ điển). Giả sử từ điển của chúng ta chỉ có 5 từ: King, Queen, Man, Woman, và Child. Ta có thể biểu diễn từ "Queen" như bên dưới:
 Ảnh: blog.acolyer.org
Ảnh: blog.acolyer.org
Nhược điểm của cách biểu diễn này là ta không thu được nhiều ý nghĩa trong việc so sánh các từ với nhau ngoại trừ so sánh bằng, các từ có ý nghĩa hơn không được nhấn mạnh.
Word2vec
Ngược lại, word2vec biểu diễn các từ dưới dạng một phân bố quan hệ với các từ còn lại (distributed representation). Mỗi từ được biểu diễn bằng một vector có các phần tử mang giá trị là phân bố quan hệ của từ này đối với các từ khác trong từ điển.
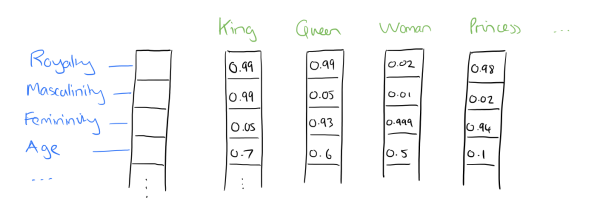 Ảnh: blog.acolyer.org
Ảnh: blog.acolyer.org
Với cách biểu diễn như vậy, người ta khám phá ra rằng các vector mang lại cho ta cả cú pháp và ngữ nghĩa ở một mức độ nào đó để máy tính hiểu.
Ví dụ:
- x(apple) – x(apples) ≈ x(car) – x(cars)
- x(family) – x(families) ≈ x(car) – x(cars)
Với x(apple) là vector của từ apple, ...
 Ảnh: blog.acolyer.org
Ảnh: blog.acolyer.org
Bạn có thể tìm hiểu kỹ hơn về Word2vec ở bài viết này.
Chuẩn bị dataset và tiền xử lý
Mình tìm kiếm bộ full Truyện Kiều trên Google, lưu vào file truyen_kieu_data.txt. Bắt đầu tiền xử lý.
1. Load tất cả các dòng vào data frame Pandas
2. Xử lý từng dòng: Xóa số dòng, bỏ chấm chấm, phẩy, ... các dấu dư thừa.
Tách từ sử dụng ngram
Để cho nhanh thay về tokenize tiếng Việt, mình sẽ sử dụng unigram (1-gram) và bigram (2-gram) để tách từ ra.
Để cho dễ hiểu thì bigram sẽ tách câu sau thành:
list(ngrams("Trăm năm trong cõi người ta".split(), 2))
> ["Trăm năm", "năm trong", "trong cõi", "cõi người", "người ta"]
Với các bigram không có nghĩa như "năm trong", "trong cõi". Word2vec cho phép tham số min_count, tức những từ này xuất hiện ít hơn n sẽ bị loại bỏ, vì chúng không có ý nghĩa trong tiếng Việt.
Combine data và word2vec với Gensim Python
Đến đoạn hay, truy vấn, tìm những từ gần nhau.
model.wv.similar_by_word("thúy kiều")
# [('thâm', 0.9992734789848328),
# ('bụi', 0.9992575645446777),
# ('lẽ', 0.9992456436157227),
# ('bắt', 0.9992380142211914),
# ('ví', 0.9992336630821228),
# ('vẻ', 0.9992306232452393),
# ('sắc', 0.999223530292511),
# ('dao', 0.9992178678512573),
# ('phen', 0.9992178082466125),
# ('hơn', 0.999215841293335)]
=> "Thâm", Nguyễn Du thật thâm thúy khi ẩn dụ về Thúy Kiều :))
model.wv.similar_by_word("tài")
# [('thiên', 0.9996418356895447),
# ('dao', 0.9996212124824524),
# ('bể', 0.9995993375778198),
# ('muôn', 0.9995784163475037),
# ('xuôi', 0.9995668530464172),
# ('00', 0.9995592832565308),
# ('nát', 0.9995554685592651),
# ('danh', 0.9995527267456055),
# ('họa', 0.9995507597923279),
# ('chờ', 0.9995506405830383)]
model.wv.similar_by_word("tình")
# [('phụ', 0.9994543790817261),
# ('âu', 0.999447226524353),
# ('nhiêu', 0.9994118809700012),
# ('50', 0.9994039535522461),
# ('40', 0.9994016885757446),
# ('cam', 0.9993953108787537),
# ('quá', 0.9993941783905029),
# ('động', 0.9993934631347656),
# ('này đã', 0.999393105506897),
# ('nhân', 0.9993886947631836)]
=> Tình không phụ sao gọi là tình
model.wv.similar_by_word("đời")
# [('nợ', 0.9996878504753113),
# ('thì cũng', 0.9996579885482788),
# ('này đã', 0.9996303915977478),
# ('miệng', 0.9996291995048523),
# ('bình', 0.999627947807312),
# ('lối', 0.999624490737915),
# ('khéo', 0.9996232986450195),
# ('cũng là', 0.999621570110321),
# ('kia', 0.9996169209480286),
# ('nhỏ', 0.9996155500411987)]
Đời là một cục nợ :D
5. PCA và visualization
PCA giảm vector word từ 100 chiều về 2 chiều, để vẽ lên không gian 2 chiều.
Kết
Word2vec chính xác khi với bộ copus thật lớn. Với ví dụ trên thực sự mục đính chỉ là vui là chính và để hiểu rõ hơn phần nào về NLP với Word2vec. Bạn nào có hứng thú có thể build các bộ Word2vec với dữ liệu cho tiếng Việt, với phần Tokenize và tiền xử lý chuẩn - word2vec sẽ hữu ích rất nhiều.
Tham khảo thêm:
- Truyện Kiều Word2vec at Github: https://github.com/duyet/truyenkieu-word2vec
- The amazing power of word vectors
- Efficient Estimation of Word Representations in Vector Space – Mikolov et al. 2013
- Distributed Representations of Words and Phrases and their Compositionality – Mikolov et al. 2013